
最近,阿里通义上线了Qwen3-TTS的两大核心能力——VoiceDesign(VD-Flash)和VoiceClone(VC-Flash)。
此次上新,甩出了两大核心能力:
据官方披露的数据显示,其生成速度达到了惊人的0.1秒级,且在多项核心指标上,直接超越了OpenAI的GPT-4o-Audio和目前国内语音霸主MiniMax。
那它的实际表现如何?我们实际体验一下。
VoiceDesign(VD-Flash):用文字“设计”声音
过去,你要找一个合适的配音,得在几十种预设音色里反复试听,总觉得“差点意思”。
现在,你只需要用自然语言描述你想要的音色,模型就能从无到有地创造出来。
比如,输入“展现出悲苦沙哑的声音质感,语速偏慢,情绪浓烈且带有哭腔,以标准普通话缓慢诉说,情感强烈,语调哀怨高亢,音高起伏大。”
能明显的听到声带因为哽咽而紧绷的摩擦感。每一句的尾音都带着无法控制的颤抖,效果非常的逼真。
或者输入一个非常简洁的指令“邪恶女魔头”。
效果依旧抗打。
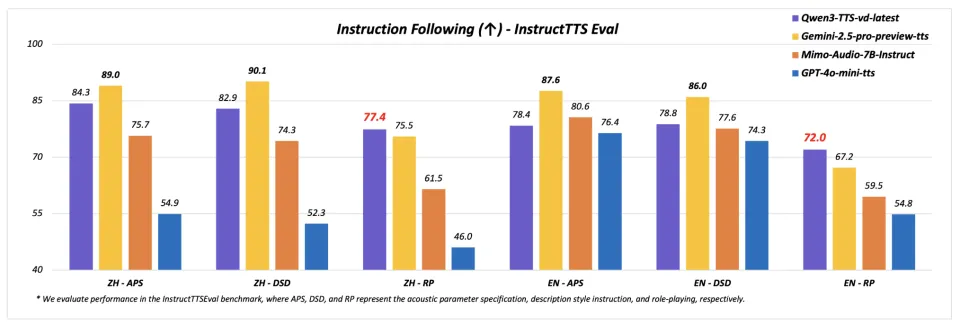
并且纸面实力也不弱,在 InstructTTS-Eval 中,Qwen3-TTS 综合表现显著优于 GPT-4o-mini-tts、Mimo-audio-7b-instruct,在角色扮演测试中也超越 Gemini-2.5-pro-preview-tts。
VoiceClone(VC-Flash):3秒音频,跨语言、跨物种级别的音色克隆。
如果说VoiceDesign是“创造声音”,那么VoiceClone就是“复刻声音”的终极形态。
只需要上传一段3-10秒的真人录音,模型就能捕捉其音色、韵律和发音特征,生成几乎一模一样的克隆语音。
这里克隆一个大家非常熟悉的声音——雷总的声音。
合成文本:前方3公里施工路段,为您切换沪昆高速。已为您预约十七点二十分到达高铁站,出口右转有蓝色遮阳棚,导航将持续为您更新路况。
可以明显地感受到,雷总的音色还原度非常高!
它不仅把雷总那股标志性的普通话味儿略带诚恳的语气”习惯都呈现出来了。
同时VoiceDesign还有跨语言能力,比如,你上传一段自己的中文录音,模型能让“你”说出地道的英语、日语或德语,而且保持音色一致性。
比如让雷总化身英语口语达人,开口说英语。
再换一个,克隆蔡徐坤的声音。
合成文本:大家好,我是蔡徐坤。1998 年出生,舞台是我的主场,音乐是我的母语。从《偶像练习生》C 位断层出道,到《Hug me》全网刷屏,我一直用原创作品说话。歌手、制作人、演员,多面身份,一样炽热。下一束灯光亮起,我会继续用舞台炸响每一次心跳。请多关照!
音色还原度依旧很高!不过这次会明显感受到声音的停顿有些许的不自然。
还有很新奇的“跨物种”克隆功能,简单来说就是,该模型能捕捉动物叫声的特征,然后让它说出人类语言(当然,这更多是娱乐应用)。
再来看纸面实力,DoiceClone(VC-Flash)的错误率比 ElevenLabs/GPT-4o 低 15%。

以前我们还在纠结AI声音不够自然,或许现在我们可能要开始担心:电话那头跟你聊天的,到底是不是真人?
目前,Qwen3-TTS 已在阿里云百炼和魔搭社区全面上线,感兴趣的可以去试玩一番。
未经允许不得转载:小花科普 » 阿里Qwen3 上新,支持跨物种声音克隆,实测复刻雷总的诚恳语气